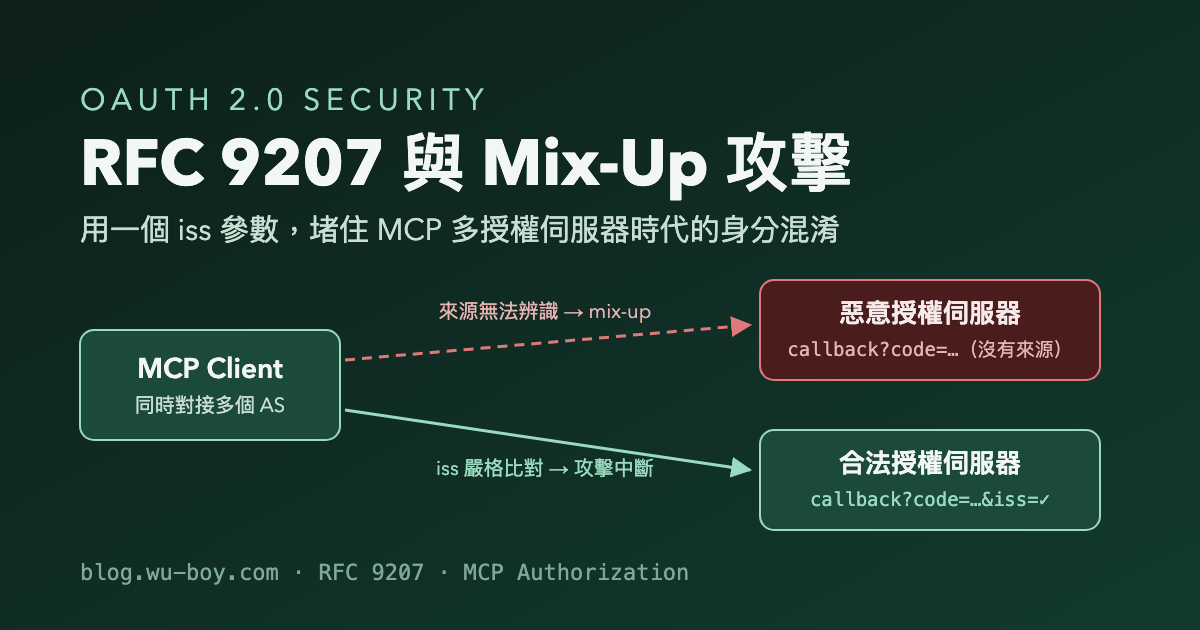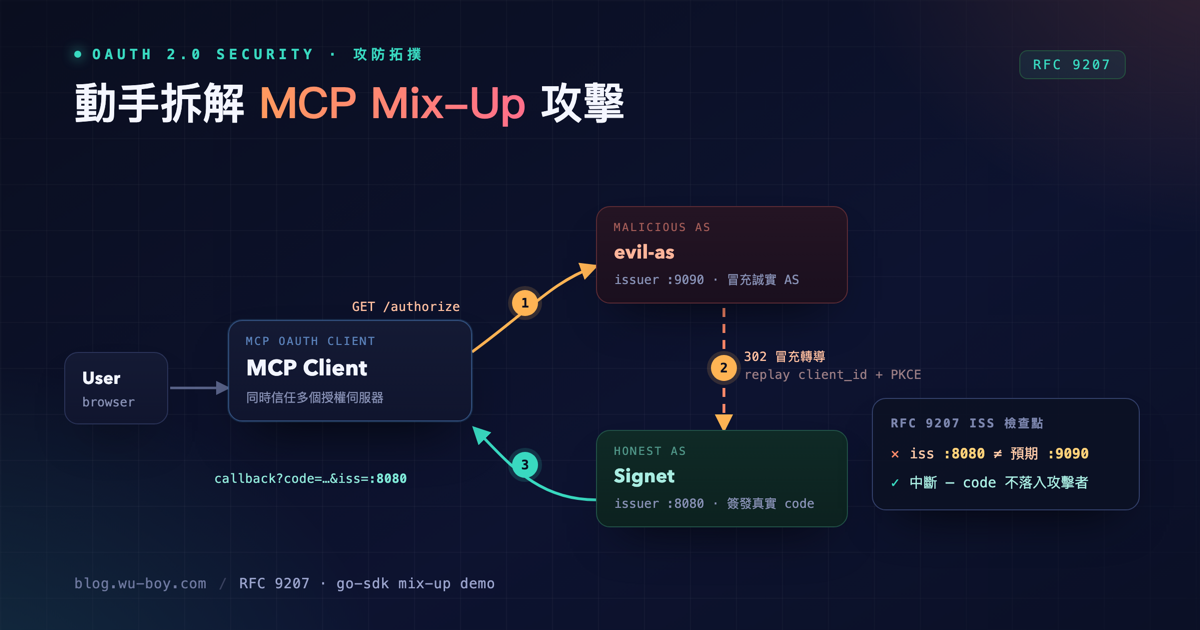
The previous post, When an MCP Client Trusts Multiple Authorization Servers: Stopping Mix-Up Attacks with RFC 9207, laid out the theory thoroughly: how the authorization-server mix-up attack works, why neither state nor PKCE stops it, and why RFC 9207’s iss parameter is the missing piece. But understanding the concept is one thing. Watching a valid authorization code get stolen and minted into a real access token is another thing entirely.
This is the hands-on companion. I take the 03-oauth-mcp/issuer-identification sample from go-training/mcp-workshop apart piece by piece: a malicious authorization server (evil-as), an MCP client that hand-rolls its OAuth flow, and an honest MCP resource server — three real Go programs you can actually run. You’ll trigger the attack yourself and watch the attacker’s terminal print STOLEN ACCESS TOKEN; then add one -defense flag and watch the same attack get cut off — by an iss comparison — before it does any harm.