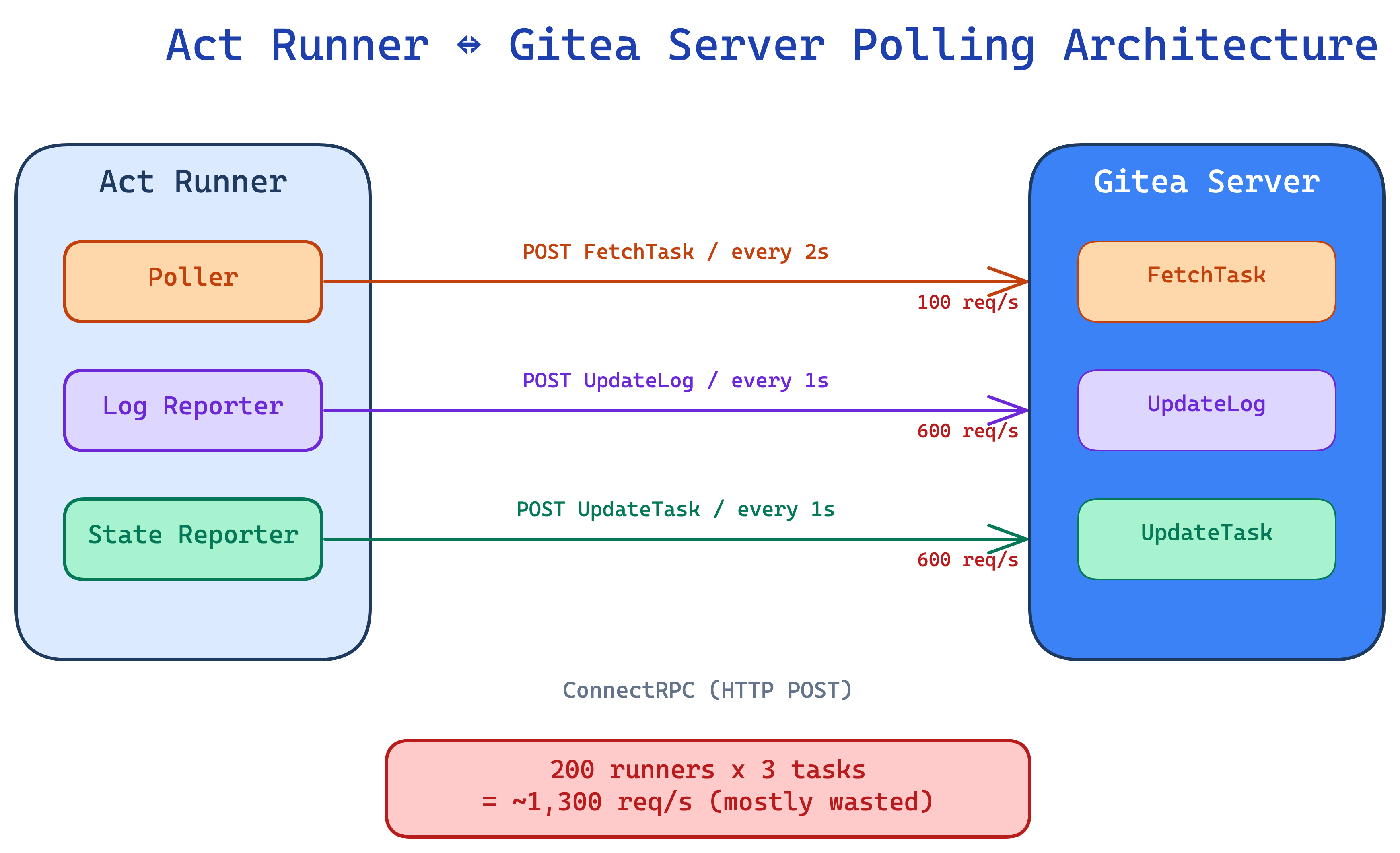
Gitea Act Runner 是 Gitea Actions 的執行元件,負責從 Gitea Server 領取 CI/CD 任務並回報執行結果。隨著越來越多團隊自架 Gitea,Runner 與 Server 之間的 HTTP 請求量成為了 Server 端的瓶頸。本文記錄我們如何分析並解決這個問題,將 200 個 Runner 的請求量從約 1,300 req/s 降到約 170 req/s,降幅 87%。
更新(2026-04-20):本文原本描述 PR #819 合併後的設計。後續 PR #822 在 code review 中揭露 #819 對
capacity > 1的 Runner 引入了一個 concurrency regression,並用「單一 poller + semaphore」架構再次修正。請見文末〈後續修正:Single Poller with Semaphore(PR #822)〉章節。
架構現狀:一切都是 HTTP Polling
Act Runner 與 Gitea Server 之間的通訊全部基於 ConnectRPC(HTTP unary request-response),沒有 streaming 也沒有 WebSocket。每次通訊都是完整的 HTTP roundtrip:
原始設計有兩個固定頻率的 timer:
- Poller:每 2 秒呼叫一次
FetchTask,無論有沒有 job - Reporter:每 1 秒呼叫
UpdateLog+UpdateTask,無論有沒有新資料
問題量化
用一個典型的中大型部署來算:200 個 Runner,平均每個跑 3 個任務。
Polling 層:
| |
Reporter 層(每個 running task 每秒 2 個請求):
| |
合計:約 1,300 req/s。其中大多數是無效請求——沒有新 job、沒有新 log、state 也沒變。
解法一:Polling Backoff with Jitter
Polling 的問題
200 個閒置的 Runner 每 2 秒發一次 FetchTask,產生 100 req/s 的無效流量。更糟的是,如果 Server 短暫當機後恢復,所有 Runner 會在同一瞬間湧入(thundering herd)。
設計:兩個獨立的計數器(per-worker)
為什麼不用一個計數器?因為「沒有 job」和「Server 掛了」是兩種不同的情境,需要不同的恢復策略:
| 情境 | empty | errors | 行為 |
|---|---|---|---|
| Server 正常,沒有 job | +1 | 歸零 | 漸進 backoff |
| Server 無回應 | 不變 | +1 | 積極 backoff |
| Server 恢復,仍無 job | +1 | 歸零 | errors 歸零但 empty 維持 backoff |
| 拿到 task | 歸零 | 歸零 | 立即回到最短間隔 |
關鍵場景:Server 當機 5 分鐘後恢復。如果只用一個計數器,恢復後第一個成功回應會把計數器歸零,所有 Runner 同時回到 2 秒間隔,造成 thundering herd。用兩個計數器,errors 歸零但 empty 繼續維持,backoff 平滑過渡。
為什麼是 per-worker 而不是共用 atomic? Act Runner 的架構是「N 個獨立的 worker,每個自己 poll 自己跑」(Capacity 控制 N)。若用共用 counter,3 個 worker 各自第一次 empty 會把 counter 推到 3,被誤判為「連續 3 次空」而觸發長 backoff——其實每個 worker 才空一次。把 counter 拆到 workerState,每個 goroutine 自己讀寫自己的 int64,不需要 atomic,也避免了這個假性 backoff 問題。順帶一個好處:當 Server 恢復、某個 worker 拿到 task 時只重置自己的 backoff,其他 worker 維持目前 interval,thundering herd 的保護更強。
⚠️ 事後修正:上面「per-worker 更好」的論述只考慮了 backoff 計數器的正確性,沒考慮到跨 worker 的 polling 節奏。舊版
rate.NewLimiter(rate.Every(FetchInterval), 1)的burst=1其實共享給所有 N 個 goroutine,實質序列化了 FetchTask 呼叫——這件事被這次改寫「意外地」消除了。capacity=60的 Runner 因此從「1 FetchTask / interval」變成「60 FetchTask / interval」,對capacity > 1的使用情境是 regression。修正請見文末〈後續修正:Single Poller with Semaphore(PR #822)〉。
指數退讓的數學
| |
退讓曲線:
用 min(n-1, 5) 限制 bit shift,因為如果 n 累積到 64 以上,1<<63 會溢位成負數。
Jitter:打散同步請求
200 個 Runner 如果同時啟動,backoff 計數器相同,計算出完全一樣的 interval。加上 ±20% 的隨機 jitter,讓請求分散在 [interval×0.8, interval×1.2] 範圍內。
為什麼是 20% 而不是 50%?太大的 jitter 會讓行為不可預測(使用者設定 5s 但實際可能 2.5s 或 7.5s)。20% 是足夠分散但不偏離預期的平衡點。這也是 AWS 推薦的 jitter 策略。
為什麼放棄 rate.Limiter?
原始設計使用 golang.org/x/time/rate.Limiter:
問題在於 rate.Limiter 建立後就是固定速率,不支援動態調整間隔,也不支援 jitter。改用 time.NewTimer 搭配每次重新計算的間隔,天然支援動態 backoff。
Fetch First, Sleep After
一個容易忽略的細節:舊版 rate.NewLimiter(..., 1) 的 burst=1 讓第一次 Wait() 立即返回,Runner 啟動或完成一個 task 後可以馬上嘗試領取下一個 job。
最初改為 timer-based 時,我們犯了一個錯誤——把 sleep 放在 fetch 前面:
正確的做法是 fetch first, sleep after——先嘗試領取,沒拿到才 sleep:
| |
這保留了 burst=1 的語意:啟動時立即 fetch,task 完成後也立即嘗試下一個,不浪費任何等待時間。
Polling 效果
| 情境 | Before | After |
|---|---|---|
| 200 個閒置 Runner | 100 req/s | ~3.4 req/s(backoff 到 60s) |
| 降幅 | — | 97% |
解法二:事件驅動的 Reporter
Reporter 的問題
原始的 RunDaemon 每秒執行兩個 HTTP 請求:
即使沒有新的 log 行、state 也沒變化,照樣發送。600 個 running task(200 runners × 3 tasks)產生 1,200 req/s。
但 CI task 的 log 輸出是間歇性的:npm install 時大量輸出,下載 Docker image 時偶爾一行,step 之間完全沉默。固定 1 秒間隔在沉默期浪費,在爆發期又沒有更快。
設計:三重觸發機制
用 goroutine + select 事件循環取代遞迴 timer:
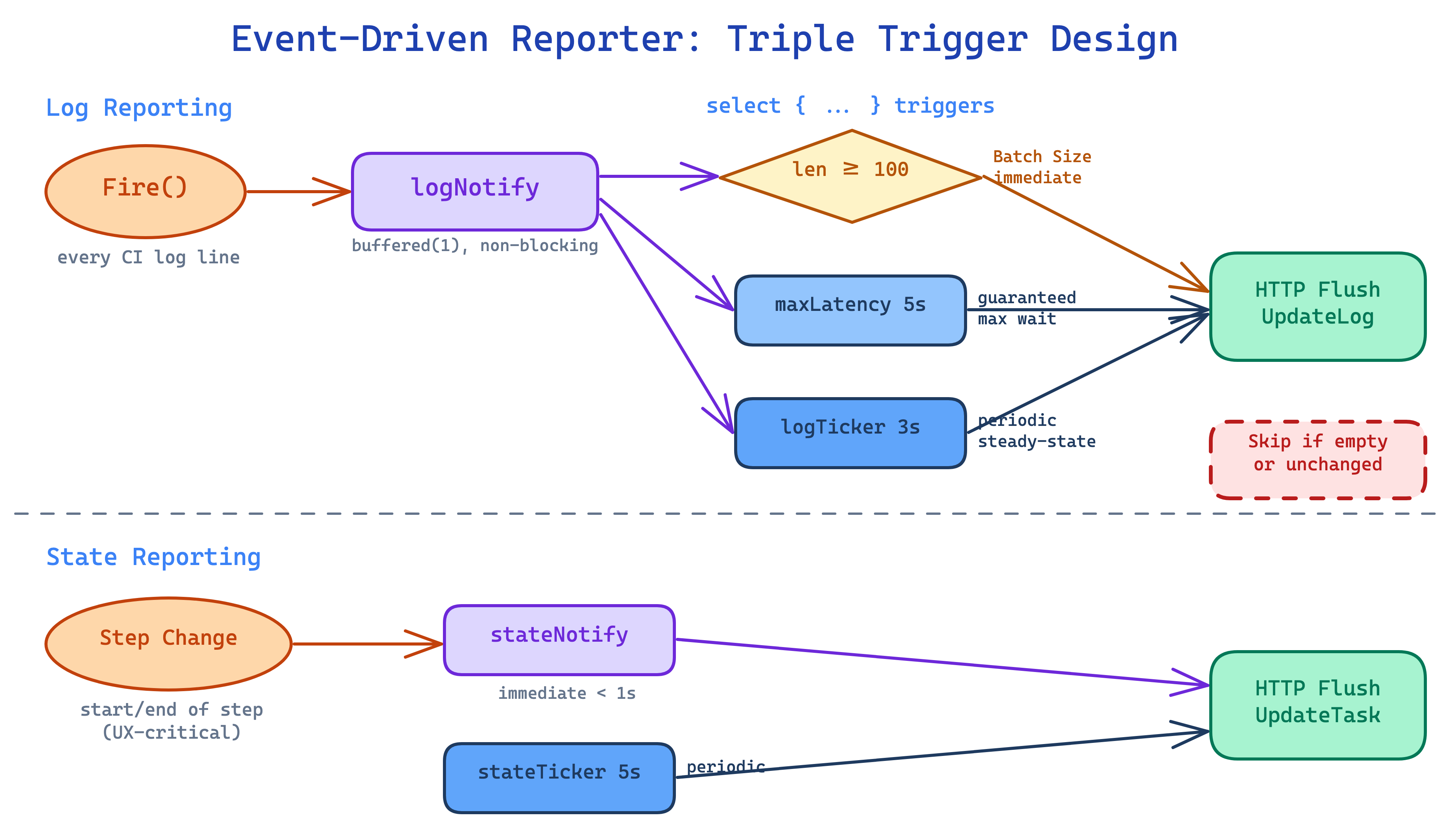
三個觸發條件各自解決不同的問題:
| 觸發條件 | 預設值 | 解決什麼 | 沒有它會怎樣 |
|---|---|---|---|
| Batch size | 100 行 | 高產出時快速送出 | npm install 輸出 500 行要等 5 秒 |
| logTicker | 5s | 穩態保底 | channel 通知可能被合併,需定時掃描 |
| maxLatencyTimer | 3s | 單行 log 不會等太久 | 一行 “Starting…” 後沉默,要等 5 秒 |
State 報告獨立為 5 秒間隔,搭配 stateNotify channel 在 step 轉換時即時 flush。
為什麼 Log 和 State 分開?
Log 和 State 的變更頻率完全不同:
| 資料 | 變更頻率 | 前端用途 | 延遲容忍度 |
|---|---|---|---|
| Log rows | 每秒數十行(burst) | 即時顯示 CI 輸出 | 3-5 秒 |
| Task state | 每個 step 轉換一次 | step 狀態圖示 | <1s(用 stateNotify) |
共用同一個 timer 就必須以最嚴格的需求來決定間隔,白白增加 state 的請求頻率。
Channel 設計:為什麼 buffered(1) + 非阻塞?
Fire() 是 logrus hook,每一行 CI log 都會經過,是 hot path。如果用 unbuffered channel,Fire() 會阻塞直到 daemon goroutine 讀取,直接拖慢 CI 執行。
buffer=1 的語意是「有新東西了」(boolean signal),不是「有幾個」。daemon 收到通知後檢查 len(r.logRows) 得知實際數量。buffer>1 沒有額外好處。
stateNotify:為什麼 Step 轉換要即時 Flush?
使用者在 Gitea UI 上看 CI build 時,最在意的是 step 從「等待」變「執行中」(轉圈動畫),以及從「執行中」變「成功/失敗」(打勾/叉叉)。這些是 UX-critical moments。如果等 5 秒的 stateTicker,使用者會感覺「卡住了」。
daemon 收到 stateNotify 後同時 flush log + state,確保 <1 秒延遲。
Skip 優化:沒變就不送
在觸發機制之外,還加了兩層 skip:
ReportLog — 空 buffer 直接 return:
ReportState — dirty flag:
為什麼用 dirty flag 而不是序列化比較(proto.Marshal → bytes.Equal)?因為 proto.Marshal 要在每次 daemon tick 序列化整個 TaskState,即使大部分時候什麼都沒變。dirty flag 是 zero-cost 的 bool 檢查。
Reporter 效果
| 情境 | Before | After | 降幅 |
|---|---|---|---|
| Log 請求(420 active tasks) | 420 req/s | 84 req/s | 80% |
| State 請求 | 126 req/s | 25 req/s | 80% |
| 合計 | ~550 req/s | ~109 req/s | 80% |
解法三:HTTP Client 調校
HTTP Client 的問題
原始程式碼在非 insecure 模式下使用 http.DefaultClient:
| |
http.DefaultClient 的 MaxIdleConnsPerHost 預設是 2。所有 Runner 請求都指向同一台 Server,當併發 goroutine(polling + 多個 task reporter)超過 2 個,多餘的 idle connection 會被關閉,下次請求需要重新建立 TCP + TLS handshake。
此外,getHTTPClient 被呼叫了兩次(PingService + RunnerService),建立了兩個獨立的連線池。
修正
| |
為什麼是 10?最大併發 ≈ 1 (polling) + capacity × 2 (每個 task 的 log + state)。預設 capacity=1 時只需 3 個,設 10 可覆蓋 capacity=4 而不浪費。
後續修正:Single Poller with Semaphore(PR #822)
上面的 per-worker 設計合併(#819)後,@ChristopherHX 在 review 中點出一個被忽略的問題:#819 把跨 worker 的序列化意外拆掉了。後續 PR #822 為這個 regression 做了結構性修正。
漏看的那件事:rate.Limiter 其實是被共享的
舊版程式碼長這樣:
burst=1 的 rate.Limiter 被所有 N 個 goroutine 共用,實務上序列化了 FetchTask 呼叫——capacity=60 的 Runner 仍然只發「1 FetchTask / FetchInterval」。
#819 把這個共用 limiter 換成 per-worker 的獨立計數器之後,這個隱性的跨 worker 序列化就消失了。capacity=60 瞬間變成「60 個各自獨立 polling 的 goroutine」,每個自己退讓、自己 jitter——從 Server 的角度看,是 60 倍的 FetchTask 流量。
實測影響:3 Runners × capacity=60
作者的生產環境是 3 個 Runner,每個 capacity=60:
| 指標 | Pre-#819(舊 rate.Limiter) | Post-#819(本文原版 per-worker) | Post-#822(single poller + semaphore) |
|---|---|---|---|
| Polling goroutines(總計) | 3 | 180 | 3 |
| 閒置時 FetchTask RPC / 週期 | 3 | 180 | 3 |
| 滿載時 FetchTask RPC / 週期 | 180(全部浪費) | 180(全部浪費) | 0(semaphore 阻塞) |
| 到 Server 的並發連線 | 3 | 180 | 3 |
值得注意的是「滿載時 0 RPC」這個特性:pre-#819 和 post-#819 都做不到——rate.Limiter 沒有 capacity 的概念,即使 N 個 slot 全部在跑 task,閒置 goroutine 還是會從 limiter 拿 token 去發 FetchTask,而 Server 回來的 task 也沒地方放。Semaphore 把 polling 和 capacity 綁在一起才解決這件事。
為什麼不 revert 回 rate.Limiter?
第一直覺是「那就把 shared limiter 加回來」。但 review 討論的結論是這不是好選擇:
rate.Limiter沒有 capacity 概念。滿載時仍然會發 FetchTask,拿回來的 task 無處可放——這是即便 pre-#819 也會浪費的 RPC。Semaphore 在這個情境下直接阻塞 polling,零浪費。- 和 #819 的 adaptive backoff 方向相反。共用 limiter 想把速率壓成固定值,per-worker backoff 想根據實際狀況動態調整——兩者疊在一起行為難以推理。
- N 個 goroutine 只為了排隊等 shared limiter 沒有意義。既然跨 worker 是序列化的,那就用 1 個 poller 直接表達這個語意,而不是讓 N-1 個 goroutine 只負責排隊。
新架構:make(chan struct{}, capacity) 當 semaphore
核心迴圈只有一個 goroutine:
| |
前文提的 exponential backoff 與 jitter 邏輯完全保留,只是跑在一份 workerState 上,不再是 N 份。
<Capacity> 在 semaphore 架構下有了明確的結構語意:「slot 數」。從 acquire slot → fetch → dispatch → release 這條不變量自動推出「polling 永遠不會比 capacity 快」。
順便修掉一個 pre-existing Shutdown bug
Shutdown() 原本長這樣:
<-p.done 會一直阻塞到 channel 被關閉,所以 Shutdown() 的 timeout 分支真要走到 shutdownJobs() 強制取消 job 時,根本走不到那行。改成真正的非阻塞檢查後才正確:
這個 bug 跟 polling 架構無關,但因為改寫 Poller 時剛好經過這段,一併修掉。
設定不變,使用者無感
capacity / fetch_interval / fetch_interval_max 所有原有設定都沿用,不需要改 config。差別只是底層實作:N 個 polling goroutine → 1 個 + semaphore。
和熔斷器(Circuit Breaker)的差異
有人可能會問:這不就是熔斷器嗎?其實不完全是。
| 維度 | 熔斷器 | 我們的 Adaptive Backoff |
|---|---|---|
| 會停止請求嗎? | 會(OPEN 狀態完全阻斷) | 不會,只是變慢(最慢 60 秒一次) |
| 狀態模型 | 三態 Closed → Open → Half-Open | 無狀態,連續的間隔計算 |
| 恢復方式 | 冷卻後試探一個請求 | 拿到 task 立即歸零 |
| 設計目的 | 快速失敗(fail-fast) | 降低無效負載 |
熔斷器適合「下游完全不可用,繼續重試只會加重負擔」的場景。我們的場景是「下游正常,只是沒有工作可做」,Backoff 更合適。如果未來需要保護 Server 過載的情境,可以在 consecutiveErrors 超過閾值時疊加熔斷器。
前端 UX 影響
所有優化都不能犧牲使用者體驗。以下是延遲對比:
| 情境 | Before | After | 為什麼可以接受 |
|---|---|---|---|
| 持續輸出(npm install) | ~1s | ~5s | CI log 不需要 sub-second 更新 |
| 單行後沉默 | ~1s | ≤3s | maxLatencyTimer 保底 |
| 大量爆發(100+ 行) | ~1s | <1s | batch size 觸發即時 flush,比原來更快 |
| Step 開始/結束 | ~1s | <1s | stateNotify 即時 flush |
| Job 完成 | ~1s | ~1s | Close() retry 機制不變 |
新增設定項
所有設定都有安全的預設值,現有設定檔無需修改:
| |
總結
| 優化項目 | 手段 | 降幅 |
|---|---|---|
| Polling | Exponential backoff + jitter | 97%(閒置 runner) |
| Log 回報 | 事件驅動 + 批次 + skip empty | 80% |
| State 回報 | 獨立間隔 + dirty flag + skip unchanged | 80% |
| HTTP 連線 | 調校連線池 + 共用 client | 減少 TCP/TLS 重建 |
| 整體 | 200 runners × 3 tasks | 1,300 → 170 req/s(87%) |
這些優化的共同原則是:不做無效的事。沒有新 log 就不發 UpdateLog,state 沒變就不發 UpdateTask,沒有 job 就逐漸降低 FetchTask 頻率。在不犧牲前端即時性的前提下,大幅減輕 Server 負擔。
而 @silverwind 在 #819 討論串裡也丟了一個更根本的方向:把 HTTP polling 換成 persistent socket(例如 WebSocket)。這樣整類「發很多請求只為了問有沒有新東西」的問題就會從架構上消失。這是相對大的改動(Server 和 Runner 雙邊都要動),目前這系列 PR 選擇在 HTTP polling 的前提下先把多餘請求壓乾,但長期來看,socket-based 協定仍然是值得投資的方向。