Over the past year, the phrase “I wrote it with AI” has gone from “worth mentioning” to “weird if you didn’t” in pull request descriptions. Anthropic internally merged a single PR of 22,000 lines — largely produced by Claude, landing in their production reinforcement-learning codebase. When that story spread, most engineers didn’t react with awe; they reacted with anxiety: if they can pull that off, what’s stopping the wave of “PMs opening Claude Code and writing production code” from hitting our team?
You can’t stop it. But you can manage it. This post is the SDLC guideline I wrote for my own team after working through Erik Schluntz’s talk Vibe coding in prod | Code w/ Claude (Erik is a coding-agent researcher at Anthropic and co-author of Building Effective Agents). The whole thesis is one sentence: enjoy the AI speedup without sacrificing code quality, maintainability, system reliability, or security.
First, Let’s Be Clear: What Vibe Coding Is and Isn’t
Here is how Andrej Karpathy originally put it:
Vibe coding is where you fully give into the vibes, embrace exponentials, and forget that the code even exists.
The key phrase is “forget that the code even exists.” If you’re still in Claude Code watching it complete every diff line by line, that’s not vibe coding — that’s AI-assisted coding. It’s essentially IDE autocomplete with a wider scope.
Real vibe coding is something else: you trust the AI to finish a whole chunk of work and verify only through abstraction layers (specs, tests, inputs and outputs) instead of reading every line. The three states differ like this:
| State | Description | Vibe Coding? |
|---|---|---|
| AI-assisted coding | Use Claude Code / Copilot for completion, engineer reviews each line | No |
| Tight feedback loop | Watch the AI line by line continuously | No |
| Real Vibe | Trust the AI for big chunks, verify only via the abstraction layer | Yes |
Erik used a sharp analogy in the talk: early compiler users would still read the assembly to make sure nothing was off, but that approach can’t scale. Eventually you have to trust the system — the only challenge is “how do I keep shipping responsibly without reading the assembly?” We’re at the early-compiler stage of AI coding right now. This guideline exists to back the act of “trusting” with concrete engineering discipline.
Why You Have to Manage It: Exponential Growth Is Compressing Your Reaction Window
A number Anthropic tracks internally: the length of tasks AI can complete is doubling every seven months.
| Time | Task scale AI can handle in one shot |
|---|---|
| Today | A day’s worth of work |
| In a year | A week’s worth of work |
| In two years | Several weeks to a month |
| In 20 years | A “computers got a million times faster” world |
For an individual the number doesn’t matter much — you can absolutely choose “no AI, I write every line myself” today, and short-term you’ll be fine. But for a team: when AI can output a week of work in one go, the person who insists on reviewing line by line becomes the bottleneck.
“Embrace the exponential” gets misread as “assume the model gets a little better.” Erik’s point is stronger than that: the model will get stronger faster than you expect, and we shouldn’t prepare for “twice as good” — we should prepare for “a million times better.” For a tech lead, that translates to:
- Don’t just buy the workflow that fits today’s tools — design a workflow that scales into the future
- Cultivate a PM mindset: if you can manage a one-day AI task today, you’ll be able to manage a one-month task later
- The marginal cost of software keeps falling, so the set of “things worth attempting” expands — but only if you can hold the quality line
The Mindset: You’re Not the Engineer, You’re Claude’s PM
“How does a CTO manage a domain expert in a field they aren’t an expert in? How does a PM accept a feature they couldn’t build? How does a CEO check the accountant’s books? These are problems every manager has handled for centuries. The only difference is: software engineers are used to understanding everything end-to-end themselves.” — Erik Schluntz
Software engineers are one of the few professions used to “understanding everything down to the metal.” But once AI scales coding work up by an order of magnitude, that habit becomes baggage. We have plenty of management wisdom to borrow from:
| Role | How they verify without doing the work |
|---|---|
| CTO managing a domain expert | Write acceptance tests |
| PM managing an engineering team | Actually use the product and check that behavior matches expectations |
| CEO managing the accountant | Spot-check the key numbers and slices they understand |
Mapped onto vibe coding:
- Like a CTO: design verifiable interfaces and tests
- Like a PM: actually use the feature, exercise the happy path and the error paths
- Like a CEO: spot-check critical boundaries, inputs/outputs, and performance numbers
This analogy has one important exception: technical debt. Most things in life have a way to verify them without understanding the implementation — but technical debt currently has no good way to be measured without reading the code. That’s why we keep vibe coding focused on the leaf nodes: contain any debt it produces in a corner where it can’t spread. That’s also the spirit of the four rules below.
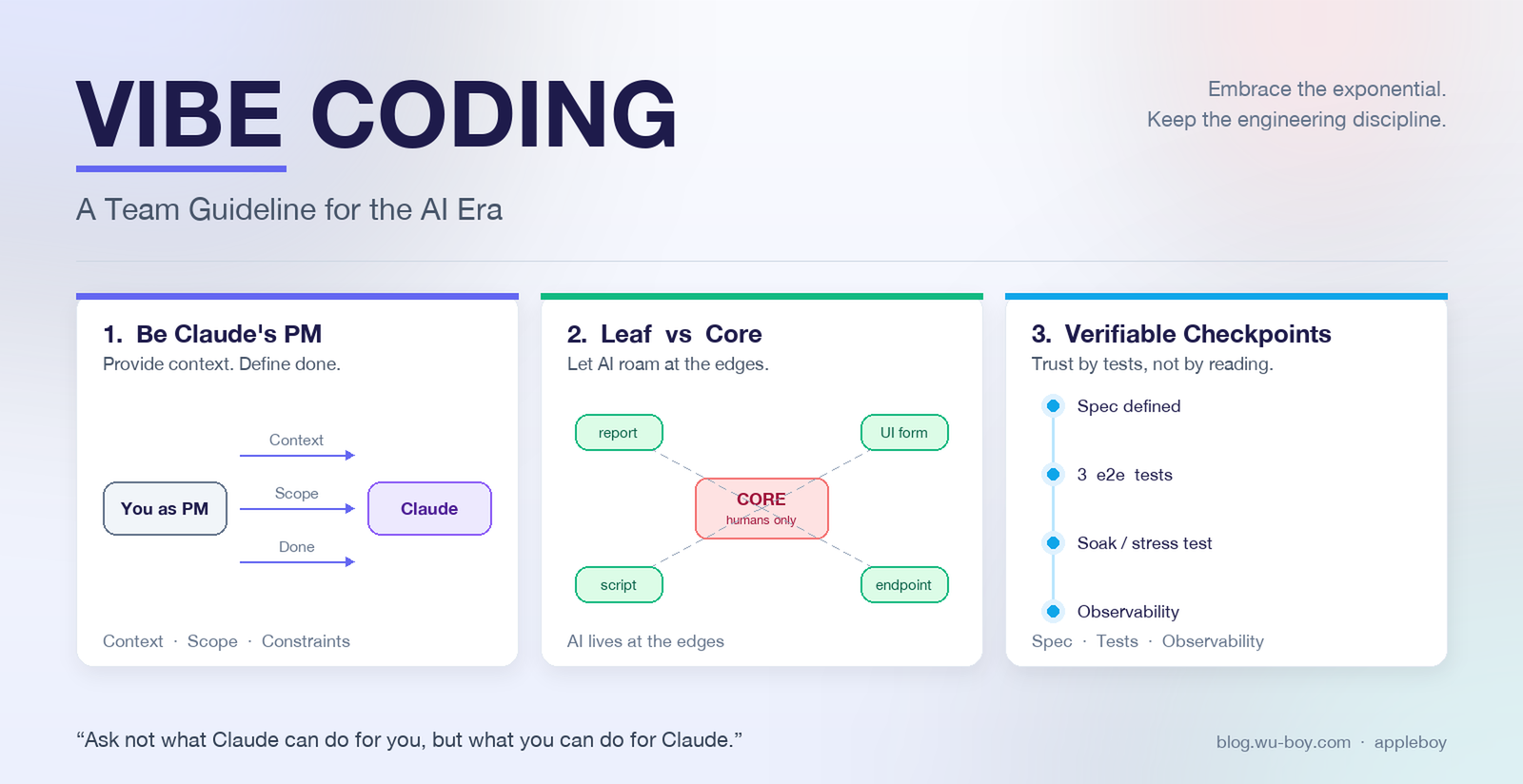
The Four Golden Rules
Rule 1: Be Claude’s PM — Give It Full Context
Imagine a brand-new hire on day one and you immediately tell them “implement this feature.” They will fail. Claude is the same.
Required:
- Spend at least 15–20 minutes gathering context before starting and consolidate it into a single prompt or plan document
- Recommended: explore the codebase with Claude in a separate conversation, co-author a plan, then open a fresh conversation to ask it to execute
- Forbidden: typing “do XXX for me” against a complex feature and hitting Enter
Context must include:
- Business requirement and the definition of “Done”
- Affected files and modules
- Code patterns to follow
- Constraints (performance, compatibility, API specs, lint rules)
- Areas you don’t want touched
Rule 2: Focus on Leaf Nodes, Stay Away from Core Architecture
“We concentrated that 22k-line change on leaf nodes — even if some debt creeps in there, it can’t spread.”
Required:
- AI-heavy code generation should stay at the leaves: utilities, single pages, single endpoints, reports, conversion scripts, UI components
- Core architecture (authn, payment, orchestrator, shared frameworks, data schema) must be human-led; AI is only an assistant
A comparison any team can relate to: writing a “send a thank-you email when a user finishes the survey” endpoint is a leaf — it serves only that flow, and if it breaks you just resend, no other feature depends on it. But touching the auth middleware that every API request passes through? That’s core — get it wrong and at best you lock legitimate users out, at worst unauthorized requests start pulling data, and the entire product line is on the line. The judgment criteria are unpacked in the next section.
Rule 3: Core Sections Get Strict Human Review
Required:
- PRs touching the core:
- At least two reviewers, one of whom is the module owner
- Reviewers must read line by line
- The PR description must explicitly mark which parts are AI-produced and which were human-reviewed
- PRs touching leaf nodes:
- At least one reviewer
- Focus on the interface contract and the tests; reading every line of the implementation is optional
Rule 4: Build Verifiable Checkpoints
“We design systems with clear inputs and outputs and verify stability with long-running stress tests, so that even without reading every line, we can confirm correctness.”
Required — every AI-heavy feature must have:
- A clear, human-readable input/output spec
- Reproducible tests (at least two of: unit / integration / e2e)
- Stability stress tests or long soak tests (for async, stateful, or resource-intensive features)
Acceptance criterion: “Even if a reviewer doesn’t read the implementation line by line, the tests and specs are enough to judge correctness.”
How to Tell Leaf Nodes from Core Code
“Leaf nodes are the parts that nothing depends on. Even if there’s some debt, it doesn’t matter — it can’t spread.”
| Dimension | Leaf Node (good for heavy vibe coding) | Core Code (must be human-led) |
|---|---|---|
| Change propagation | Only affects a few callers | Depended on by many modules |
| Expected change frequency | Won’t change much in the short term | Continuously evolving, must stay extensible |
| Tolerance for tech debt | Tolerates a bit | Does not tolerate it |
| Typical examples | Reports, conversion, single endpoint, UI components, scripts, one-off migrations | Auth, billing, domain model, framework, public API, data schema |
| Failure cost | Localized, easily rolled back | System-wide, affects users / data |
| Strict review required? | Spot-check is enough | Line-by-line review |
Rule of thumb: ask yourself “if this code goes wrong, how far does the impact spread?” — the further, the more it belongs to core.
Dynamic adjustment: model capability keeps increasing. As newer models stabilize, the core/leaf boundary will gradually push into core. The tech lead should revisit this classification every quarter.
Designing for Verifiability: Reviewers Should Trust Without Reading the Implementation
Ask yourself during design: can a reviewer judge correctness without reading the implementation?
Interface-First
- Every function/API needs explicit input/output types and documentation
- Side effects (DB writes, external calls) must be declared at the interface layer
Test Coverage
| Code type | Required tests |
|---|---|
| Pure function / utility | Unit tests (with edge cases) |
| Endpoint / API | Integration tests (happy path + error paths) |
| Async / scheduled / long-running | Stress test or long soak test |
| UI component | Snapshot / interaction test |
Observability
- Critical flows must have logs, metrics, and traces
- Failures must be detectable by monitoring, not just dropped as a stack trace
A Concrete Example
| |
SOP: Plan-then-Execute
The full vibe coding workflow looks like:
| |
Skipping Steps 1–3 to jump straight to Step 4 is forbidden. That’s the floor of this guideline; PRs that violate it get sent back.
When to Compact or Open a New Session
The principle is simple: “if I were a human engineer, would I get up for lunch and come back at this point?” If yes — it’s time to compact.
Typical compact moments:
- Right after exploring the codebase and producing the plan (the context is already saturated with exploration tokens)
- After finishing a sub-task, before moving to the next
- When the conversation starts producing “function-name drift” (variable names keep shifting)
Warning signs of decay from a too-long conversation:
- Function names become inconsistent across the conversation
- Even with guiding documents, it keeps drifting off topic
- Repeats the same mistake
Don’t power through it — compact immediately or start a new session and feed it a slim plan.
Exploration SOP for Unfamiliar Codebases
Vibe coding directly on an unfamiliar codebase is high risk: you can’t tell whether the AI’s decisions are reasonable, and you can’t yank it back when it goes off the rails. Do these four steps before you start:
- Ask the lay of the land: “Tell me where auth is handled in this codebase. Which file owns X?”
- Find similar features: “List features similar to X, with file names and class names.”
- Build a mental map: read the key files yourself based on the answers and form an architectural mental map
- Then start writing the feature: only now move into plan production
Prompting and TDD: Be Specific, Don’t Strangle the Model
Six Required Elements of a Prompt
- Goal: what problem are we solving and who uses it
- Scope: which files can be touched, which can’t
- Existing patterns: please follow the structure of
xxx.ts - Constraints: performance / compatibility / no new dependencies
- Verification criteria: which tests should pass when you’re done
- Definition of Done
Over-Constrained Prompts Make the Model Worse
“Our models perform best when they’re not over-constrained. Don’t pour effort into ultra-strict prompt templates — treat the prompt as guidance you’d give a junior engineer, no more.”
The judgment call:
- Don’t care about implementation details → just give the requirement and the definition of Done
- Want to follow existing architecture → point to the file to follow and the classes to use
- Avoid: hardcoding every variable name and every line of logic into the prompt
A Good Prompt Example
| |
Compare with the bad version: “add an activity report API for me.” No scope, no patterns, no constraints, no verification — the AI is left to improvise, and the output is high risk.
TDD with Vibe Coding: Three Minimal e2e Tests
Erik’s practical recommendation: tell Claude explicitly to “write only three end-to-end tests: one happy path and two error scenarios.” This avoids:
- Writing piles of tests glued to implementation details
- So many tests that reviewers stop reading them
- Having to update tons of tests on every refactor
The order matters: give the test spec first, then ask the AI to write the implementation.
“Most of the time, after vibe coding I only read the tests. If the tests look reasonable and they pass, I have confidence in the code.”
That’s the concrete realization of “verifiability.”
Floor of the rule:
- Each leaf-node feature gets at least 3 e2e tests
- Tests must live at the “user can understand” level, not internal implementation details
- For core code changes, tests are written / reviewed by a human
Mapping It to the SDLC: How Vibe Coding Fits Into Your Existing Pipeline
A lot of teams read the rules above and ask the same thing: “how do we integrate this with our current SDLC?” The answer — don’t build a parallel process; add an “AI-change gate” to every existing SDLC stage. Mapping table:
| SDLC stage | Without AI | Extra requirement with AI |
|---|---|---|
| Requirements | Write user stories, define Done | Add: “Is this change leaf or core?” — wrong classification sends it back to requirements |
| Design | Interfaces, data flow, error handling | Add a “verifiability” section: can a reviewer trust without reading the implementation? |
| Development | Write code, run tests locally | Plan-then-Execute SOP; Steps 1–3 are mandatory; compact when the conversation balloons |
| Testing | Unit / integration | Leaf requires at least 3 e2e tests (happy + 2 errors); long-running services require soak tests |
| Review | Peer review | Apply different intensity by leaf/core; core needs two reviewers reading line by line; PR must mark AI-produced scope |
| Deployment | CI/CD, canary, monitoring | Critical flows must have logs/metrics/traces; failures must surface to monitoring, not just stack traces |
| Operations | On-call, incident retro | Re-review the leaf/core classification every quarter; add to the retro: “Was this incident related to AI output?” |
A note: the guideline isn’t trying to upend your SDLC — it’s about turning “is the AI a new hire, do we let it work on this?” into a standard question at every stage. Requirements asks “should we let the AI do this?”, design asks “how do I verify what the AI produces?”, review asks “did anyone actually read the AI’s part?”, and operations asks “should the classification rules change?” The earlier the gate catches it, the less you step on a mine downstream.
Pull Request Template
Save the following as .github/pull_request_template.md. All PRs must fill it in.
| |
Code Review Guideline
As a reviewer, you’re not reviewing the AI’s work — you’re reviewing whether the PR author did the PM job properly.
Order of review focus:
- Is the PR description complete? (send back if not)
- Does the implementation match the plan?
- Does the change scope match the leaf/core classification?
- Are interfaces and tests clear?
- For core sections, walk through the logic line by line
- For leaf nodes, spot-check; focus on tests and edge cases
Standard reasons to send a PR back (copy-paste these to the author):
- No plan.md or plan summary
- Core code changes lack a record of line-by-line review
- No stress test, but this is a long-running service
- Tests cover only the happy path
- Touched scope explicitly marked “must not change” in the PR
- Tests are too tied to implementation details, not e2e level
Two review-comment styles for contrast:
Anti-Patterns
The following behaviors are not allowed into main; PRs that violate them are sent back:
- The “one prompt → straight to commit” workflow
- AI heavily changes core code without line-by-line review
- PR has no tests, only “I ran it and it worked”
- PR doesn’t mark the AI-produced scope
- Heavy AI generation in a domain you don’t know (when you can’t tell right from wrong, take small steps instead)
- “Mega AI PR” spanning multiple core modules — split into multiple leaf-node PRs
- Pasting AI error messages straight back into the prompt and retrying repeatedly without thinking about the cause
- Reviewer approving because “I don’t get it, so I trust the AI”
- Over-constrained prompts (every name hardcoded) that degrade model performance
- Pushing through ballooning context without compacting, leading to function-name drift
- Vibe coding code that handles secrets / payment / auth
Common Scenario Decision Table
Not sure if a task is fit for vibe coding? Look it up:
| Scenario | Recommendation |
|---|---|
| Add a new internal report | Good for vibe coding (leaf node) |
| Refactor the payment flow | Core code; AI assists, human leads |
| Write a one-off data migration | Good for vibe coding, but verification scripts must be rigorous |
| Replace the ORM | Not pure vibe coding; needs an architecture RFC |
| Add a UI form | Good for vibe coding |
| Change auth middleware | Core code, line-by-line review |
| Add a 24-hour cron job | Vibe-codable, but must include a soak test |
| Fix a small bug | Vibe-codable, but tests must cover the bug |
| Introduce a new framework | Architectural decision; needs an RFC |
| Add a feature in an unfamiliar codebase | Run the exploration SOP first, then vibe code |
| Handle user PII / payments | Must be human-led, core-level review |
| Write a small game / side project | Vibe code freely; this guideline doesn’t apply |
Roles and Responsibilities
| Role | Responsibility |
|---|---|
| Author | Acts as Claude’s PM; provides full context; self-verifies; honestly marks AI-produced scope |
| Reviewer | Checks that the process is followed; line-by-line on core; spot-checks on leaf |
| Module Owner | Guards the core architecture; has veto power on AI PRs touching their module |
| Tech Lead | Enforces the guideline; periodically audits AI PR quality; revisits leaf/core classification quarterly; decides policy adjustments on model upgrades |
| Every member | Continuously level up “asking the AI questions and verifying answers” — this is the future core skill |
Closing: Embrace the Exponential, Hold the Discipline
“You can choose not to use AI for coding today. But in a year or two, if you still insist on writing every line yourself, you’ll be the bottleneck. Remember the exponential — this isn’t science fiction, it’s the product roadmap.” — Erik Schluntz
It’s reasonable to worry that “engineers today don’t go through the bare-handed pain that we used to have to suffer through” — but the flip side is that learning with AI is many times faster than before. Architecture decisions used to take two years to validate; today you can verify in six months. Anyone willing to put in the time can stack 4× the experience in the same window. What we should actively avoid is the “swipe through and ship” mindset: not understanding the AI’s output, only chasing green CI and a merged PR — short-term it ships, but long-term you lose the ability to judge whether the AI is right.
The spirit of this guideline can be compressed into one line:
Ask not what Claude can do for you, but what you can do for Claude.
Treat yourself as the PM and treat Claude as a capable teammate that needs clear direction. Focus on leaf nodes, guard the core, build verifiable checkpoints, and learn to compound experience on top of AI — that’s how a team keeps shipping high-quality products in the vibe coding era.
If your team doesn’t have any guideline in place yet but people are already secretly using AI to write production code, my recommendation is to start from the minimum viable subset: ship the PR template, require AI-scope marking, and add the leaf/core split. Just those three things will block most of the disasters. The rest can grow with the team.
Talk source: Erik Schluntz, Vibe coding in prod | Code w/ Claude