過去一年,「我用 AI 寫的」這句話在 Pull Request 描述裡出現的頻率,已經從「值得一提」變成「沒寫才奇怪」。Anthropic 內部曾合併過一個 22,000 行、由 Claude 大量產出、最後跑進正式環境強化學習程式碼庫的 PR——這件事傳出來的時候,多數工程師的第一反應不是讚嘆,而是焦慮:如果他們做得到,那我們團隊憑什麼擋得住「PM 直接開 Claude Code 寫 production code」的浪潮?
擋不住。但可以管好。這篇文章是我整理 Erik Schluntz(Anthropic 編程智能體研究員、《Building Effective Agents》共同作者)演講「Vibe coding in prod | Code w/ Claude」之後,為自己團隊寫的一份 SDLC 規範。核心命題只有一句:在享受 AI 加速的同時,不犧牲程式品質、可維護性、系統穩定性與資安。
先講清楚:什麼是 Vibe Coding,什麼不是
Andrej Karpathy 最早把這個詞丟出來的時候是這麼說的:
Vibe coding is where you fully give into the vibes, embrace exponentials, and forget that the code even exists.
關鍵在「忘記程式碼存在」這七個字。如果你還在 Claude Code 裡逐行盯著它補完每一個 diff,那不是 vibe coding,那是 AI 輔助寫 code——本質上跟 IDE 自動補全沒兩樣,只是補的範圍變大。
真正的 vibe coding 是另一回事:你信任 AI 完成一整塊工作,只透過抽象層(規格、測試、輸入輸出)驗證,不讀完每一行。三種狀態的差別整理如下:
| 狀態 | 描述 | 是否屬於 Vibe Coding |
|---|---|---|
| AI 輔助寫 code | 用 Claude Code / Copilot 補完,工程師逐行 review | 不是 |
| 緊密回饋迴圈 | 持續一行一行盯著 AI 看 | 不是 |
| 真正 Vibe | 信任 AI 完成大塊工作,只透過抽象層驗證 | 是 |
Erik 在演講裡用了一個我覺得很到位的類比:早期使用編譯器的人會去讀組合語言確認沒問題,但這做法沒辦法 scale。最終你必須信任系統——挑戰只在於:「如何在不讀組合語言的情況下,仍然能負責任地交付產品?」我們現在面對 AI 編程,正處於早期編譯器的階段。這份規範,就是為了讓「信任」這件事有具體的工程紀律支撐。
為什麼非管不可:指數成長正在壓縮你的反應時間
Anthropic 內部追蹤的一個數字:AI 能完成的任務長度,每 7 個月翻倍一次。
| 時間點 | AI 能一次處理的任務量等級 |
|---|---|
| 現在 | 一天的工作量 |
| 一年後 | 一週的工作量 |
| 兩年後 | 數週到一個月 |
| 二十年後 | 「電腦快了一百萬倍」的世界 |
這個數字對個人決策意義不大——你今天當然可以選擇「不用 AI」、「每行 code 都自己寫」,短期沒問題。但對團隊來說:當 AI 可以一次產出一週的工作量時,仍堅持逐行審閱的人會直接變成團隊的瓶頸。
「Embrace the exponential」這句口號常被誤解成「假設模型會變好一點點」。Erik 強調的不是這樣:模型會變得比你預期還快地變強,我們不該用「兩倍好」的方式準備未來,而是要用「百萬倍好」的方式準備自己。對 Tech Lead 的具體含意:
- 不要只買「現在」的工具流程,要設計能擴展到未來的工作模式
- 培養 PM 視角——今天能管 1 天的 AI 任務,將來才能管 1 個月的
- 軟體邊際成本下降,「敢做的事」會變多——但前提是品質紀律守得住
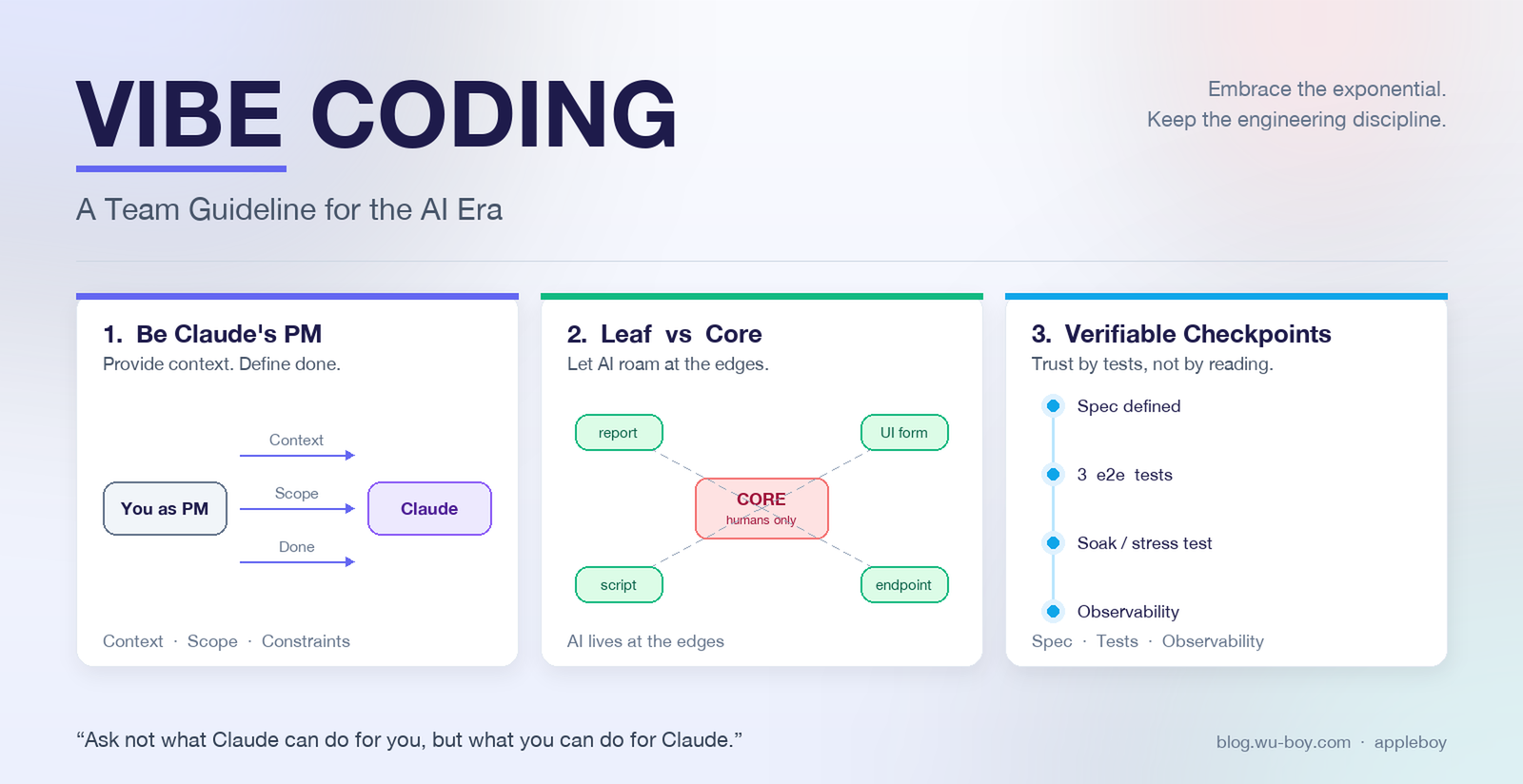
心法:你不是工程師,你是 Claude 的 PM
「CTO 怎麼管理一位他自己不是專家的領域專家?PM 怎麼驗收一個自己不會寫的功能?CEO 怎麼檢查會計師的帳?這些都是延續了上千年的問題,每個 manager 都在處理。差別只在:軟體工程師習慣自己什麼都懂到底。」 — Erik Schluntz
軟體工程師是少數「習慣自己什麼都懂到底」的職業。但隨著 AI 把編碼工作放大一個量級,這份習慣會變成包袱。我們其實有大量現成的管理智慧可以借用:
| 角色 | 不懂實作但仍能驗證的方法 |
|---|---|
| CTO 對領域專家 | 寫驗收測試 (acceptance tests) |
| PM 對工程團隊 | 真的去用產品,確認行為符合預期 |
| CEO 對會計師 | 抽查自己懂的關鍵數據與切片 |
對應到 vibe coding:
- 像 CTO:設計可驗證的介面與測試
- 像 PM:真的把功能用起來,測 happy path 與錯誤路徑
- 像 CEO:抽查關鍵邊界、輸入輸出、效能數據
這個類比有一個重要例外:技術債。人生中大部分要驗證的事情,都有不需要懂實作就能驗證的方法——但技術債目前沒有好方法在不讀程式碼的情況下衡量。所以我們才需要把 vibe coding 聚焦在 leaf node:把可能產生的技術債限制在不會擴散的角落。這也是下面四大法則的核心精神。
四大黃金法則
法則一:Be Claude’s PM——為它提供完整上下文
想像一位新員工第一天上班,你直接丟給他「實作這個功能」——他不可能成功。Claude 也一樣。
規範要求:
- 動工前至少花 15–20 分鐘蒐集上下文,整理成單一 prompt 或計畫文件
- 建議做法:先在另一個對話裡與 Claude 探索 codebase、共同產出計畫,再開新對話請它執行
- 禁止做法:對著一個複雜功能直接打「幫我做 XXX」就按 Enter
Context 必須包含:
- 商業需求與「Done」的定義
- 受影響檔案與模組
- 應遵循的程式碼模式 (pattern)
- 限制條件(效能、相容性、API 規格、Lint rules)
- 不希望被改動的範圍
法則二:聚焦 Leaf Nodes,遠離核心架構
「我們把那個 22k 行的變更集中在 leaf nodes,因為那裡即使有點技術債,也不會擴散。」
規範要求:
- AI 大量生成的程式碼應集中在葉節點:utilities、單一頁面、單一 endpoint、報表、轉檔腳本、UI 元件
- 核心架構(authn、payment、orchestrator、共用 framework、資料 schema)必須由人主導,AI 僅作輔助
舉個任何團隊都遇得到的對比:寫一個「使用者填完問卷後自動寄感謝信」的 endpoint,是 leaf——只服務這條流程,壞了補寄一次就好,沒有別的功能依賴它。但去動所有 API 都會經過的 auth middleware?那是 core——它一旦寫錯,輕則把合法使用者擋在門外,重則讓未授權的請求拿到資料,整條產品線都會被它牽動。判定標準下節再展開。
法則三:核心區塊由人嚴格 Review
規範要求:
- 觸及核心區塊的 PR:
- 至少兩位 reviewer,其中一位為該模組的 owner
- reviewer 必須逐行閱讀
- PR 描述需明確標示 AI 產出的範圍與人類審閱的範圍
- 觸及 leaf node 的 PR:
- 至少一位 reviewer
- 重點審查介面契約與測試,可不必逐行讀實作
法則四:建立可驗證的檢查點 (Verifiable Checkpoints)
「我們設計系統有清楚的輸入輸出,並用長時間 stress test 驗證穩定性,這樣即使不讀完所有程式碼,也能確認正確性。」
規範要求——每一個 AI 大量產出的功能都必須具備:
- 明確且人類可讀的輸入/輸出規格
- 可重現的測試(unit / integration / e2e 至少擇二)
- 針對穩定性的壓力測試或長時間執行測試(針對非同步、stateful、資源密集型功能)
驗收標準:「即使 reviewer 沒有逐行讀實作,也能透過測試與規格判斷正確性」。
Leaf Node vs Core Code 怎麼分
「Leaf nodes 是沒有東西依賴它們的部分。即使有技術債也沒關係,因為不會擴散。」
| 維度 | Leaf Node(適合大量 Vibe Coding) | Core Code(須人類主導) |
|---|---|---|
| 變更傳播範圍 | 只影響呼叫此模組的少數位置 | 被許多模組依賴 |
| 預期變動頻率 | 短期內不會再大改 | 持續演進、需可擴展 |
| 技術債容忍度 | 容忍少量技術債 | 不容忍技術債 |
| 典型例子 | 報表、轉檔、單一 endpoint、UI 元件、scripts、單次性遷移 | Auth、Billing、Domain Model、Framework、Public API、Data Schema |
| 失敗成本 | 區域性、可快速回滾 | 全系統性、影響使用者/資料 |
| 是否需嚴格 Review | 抽查即可 | 逐行 review |
判斷小技巧:問自己「如果這段程式碼出錯,影響會擴散多遠?」——擴散越遠越屬於 core。
動態調整:模型能力會持續變強。隨著新模型穩定性提升,core / leaf 的分界線會逐漸往 core 推進。Tech Lead 應每季重新檢視這個分類清單。
可驗證性設計:讓 reviewer 不讀實作也能信任
設計階段就要問自己:Reviewer 不讀實作能判斷正確嗎?
介面優先 (Interface-First)
- 函式 / API 必須有明確的輸入輸出型別與文件
- 副作用(DB 寫入、外部 call)需在介面層說明
測試覆蓋
| 程式類型 | 必備測試 |
|---|---|
| Pure function / utility | Unit test(含邊界條件) |
| Endpoint / API | Integration test(happy path + 錯誤路徑) |
| 非同步 / 排程 / 長時運行 | Stress test 或長時間 soak test |
| UI 元件 | Snapshot / interaction test |
可觀測性
- 重要流程須有 log、metric、trace
- 失敗能被監控察覺,而非只丟出 stack trace
一個對照例子
工作流程 SOP:Plan-then-Execute
整個 vibe coding 工作流長這樣:
| |
禁止跳過 Step 1–3 直接進入 Step 4。 這是規範底線,違反這條的 PR 直接退回。
何時該 Compact 或開新 Session
判斷原則很簡單:「如果我是人類工程師,這時候我會起身去吃午餐然後再回來嗎?」 如果是——該 compact 了。
典型 compact 時機:
- 探索完 codebase、產出計畫之後(這時 context 已被探索 token 灌爆)
- 完成一個子任務、要進入下個子任務之前
- 對話長到開始發生「函式名稱漂移」(變數名變來變去)
對話太長導致的退化警訊:
- 函式名稱前後不一致
- 即使建立了引導文件,仍偏離主題
- 重複犯同一個錯誤
不要硬撐,立即 compact 或開新 session 並餵入精簡 plan。
陌生 Codebase 的探索 SOP
不熟悉的 codebase 上直接 vibe code 是高風險行為:你無法判斷 AI 的決策是否合理,也無法在它走錯時及時拉回。動工前先做四步:
- 問場域:「告訴我這個 codebase 中哪裡處理 auth?哪個檔案負責 X?」
- 找類似功能:「告訴我跟 X 類似的功能有哪些?列出檔案名與 class 名。」
- 建立心智圖:根據以上資訊自己讀關鍵檔案,建立架構心智圖
- 才開始寫功能:此時才進入計畫產出階段
Prompt 撰寫與 TDD:給規範,不給綁手綁腳
Prompt 必備六元素
- 目標:要解決什麼問題、誰會用
- 範圍:可以動哪些檔案、不可以動哪些
- 既有模式:請參考
xxx.ts的寫法 - 約束:效能 / 相容性 / 不可引入新依賴
- 驗證標準:完成後跑哪些測試應該通過
- Done 的定義
過度約束反而會讓模型表現變差
「我們的模型在沒被過度約束時表現最好。不要花太多力氣設計超嚴格的 prompt 模板,把它當成你給 junior 工程師的引導即可。」
判斷原則:
- 不在乎實作細節 → 只給需求與 Done 的定義
- 想沿用既有架構 → 指定要參考哪個檔案、要用哪些 class
- 避免:把每個變數命名、每行邏輯都寫死在 prompt 裡
好 Prompt 範例
| |
對照糟糕版本——「幫我加一個活躍度報表 API」。缺乏範圍、模式、約束、驗證,AI 只能自由發揮,產出風險極高。
TDD 配 Vibe Coding:3 條極簡 e2e 測試
Erik 的實戰建議:明確告訴 Claude「只寫三條 end-to-end 測試:一條 happy path、一條錯誤情境、另一條錯誤情境」。這樣可以避免:
- 寫了一堆綁太死實作細節的測試
- 測試多到 reviewer 不想看
- 每次重構都要改一堆測試
撰寫順序很重要:先給測試規範,再讓 AI 寫實作。
「很多時候我 vibe coding 後,只讀測試。如果測試合理、且測試通過,我就對程式碼有信心。」
這就是「可驗證性」的具體落實。
規範底線:
- 每個 leaf node feature 至少 3 條 e2e 測試
- 測試必須是「使用者能理解的層級」,不是內部實作細節
- core code 改動,測試由人類主導撰寫 / 審閱
對應到 SDLC:vibe coding 怎麼塞進團隊既有流程
很多團隊讀完上面的法則會問同一個問題:「這跟我們現有的 SDLC 怎麼整合?」答案是——不另外造一條新流程,而是把每個 SDLC 階段都加上一道「AI 變更專屬的閘門」。對照表如下:
| SDLC 階段 | 沒 AI 時做的事 | 有 AI 時的額外要求 |
|---|---|---|
| 需求 | 寫 user story、定義 Done | 多寫一句:「這個變更屬於 leaf 還是 core?」——分類錯就回到需求重審 |
| 設計 | 介面、資料流、錯誤處理 | 多一個「可驗證性設計」段落:reviewer 不讀實作能信任嗎? |
| 開發 | 寫 code、本地跑測試 | Plan-then-Execute SOP;Step 1–3 不可省略;對話爆量就 compact |
| 測試 | unit / integration | leaf 強制至少 3 條 e2e(happy + 2 errors);長時運行強制 soak test |
| Review | 同儕 review | 依 leaf / core 套用不同強度;core 兩位 reviewer 逐行;PR 必須標示 AI 產出範圍 |
| 部署 | CI/CD、灰度、monitoring | 重要流程必須有 log / metric / trace;失敗能被監控察覺,不能只是 stack trace |
| 維運 | on-call、事故 retro | 每季重檢 leaf / core 分類清單;retro 加一題:「這次事故跟 AI 產出有沒有關係?」 |
敘述補充: 這套規範不是要顛覆現有 SDLC,而是把「AI 是不是新員工、要不要讓他做這件事」變成每個階段的標準提問。需求階段問「該讓 AI 做嗎」、設計階段問「AI 做完我要怎麼驗」、Review 階段問「AI 做的部分有沒有人讀過」、維運階段問「分類規則該不該動」。閘門越前面把得越好,後面踩到雷的機率就越低。
Pull Request 模板
把以下內容存為 .github/pull_request_template.md,所有 PR 必須填寫:
| |
Code Review 準則
身為 reviewer,你不是在檢查 AI 的工作,你是在檢查送 PR 的人有沒有做好 PM 的工作。
Review 重點順序:
- PR 描述是否完整(缺則退回)
- 計畫與實作是否一致
- 變更範圍是否符合 leaf / core 分類
- 介面與測試是否清楚
- Core code 區塊逐行檢視邏輯
- Leaf node 區塊抽查、重點看測試與邊界
標準退回理由(直接複製貼給 author):
- 沒有 plan.md 或計畫摘要
- Core code 變更缺少逐行 review 紀錄
- 沒有 stress test,但這是長時間執行的服務
- 測試只有 happy path
- 動到了 PR 中聲明「不可動」的範圍
- 測試太綁實作細節,不是 e2e 等級
對比兩種留言風格:
禁止事項 (Anti-Patterns)
以下行為禁止進入 main 分支,違反者 PR 直接退回:
- 「一句 prompt → 直接 commit」的工作流
- AI 大量改動 core code 卻未逐行 review
- PR 沒有測試,只有「我跑過了沒問題」
- PR 沒有標示 AI 產出範圍
- 在不熟悉的領域用 AI 大量產出(你無法判斷對錯時,請改為小步前進)
- 跨多個 core 模組的「巨型 AI PR」——應拆成多個 leaf-node PR
- 把 AI 的錯誤訊息原封不動貼回 prompt 反覆試錯,不思考原因
- Reviewer 因為「看不懂所以信任 AI」而 approve
- Prompt 過度約束(每行命名都寫死)導致模型表現變差
- 對話 token 數爆量還硬撐不 compact,導致函式名稱漂移
- 對處理 secrets / payment / auth 的程式做 vibe coding
常見情境決策表
不知道某個任務適不適合 vibe coding?查表:
| 情境 | 建議做法 |
|---|---|
| 想加一個新的內部報表 | 適合 Vibe Coding(leaf node) |
| 想重構支付流程 | Core code,AI 僅作輔助、必須人主導 |
| 想寫一次性資料遷移腳本 | 適合 Vibe Coding,但驗證腳本要嚴謹 |
| 想換掉 ORM | 不適合單純 Vibe Coding,需架構設計 RFC |
| 想加個 UI 表單 | 適合 Vibe Coding |
| 想改 auth middleware | Core code,逐行 review |
| 想加一個 cron job 跑 24 小時 | 可 Vibe Coding,但必須有 soak test |
| 修一個小 bug | 可 Vibe Coding,但仍需測試覆蓋該 bug |
| 想引入新框架 | 屬於架構決策,須先 RFC |
| 不熟的 codebase 想加新功能 | 先做探索 SOP,再進入 vibe coding |
| 處理使用者 PII / 金流 | 必須人主導,core code 等級 review |
| 寫個小 game / side project | 隨意 vibe code,本規範不強制 |
角色與責任
| 角色 | 責任 |
|---|---|
| Author | 扮演 Claude 的 PM;提供完整 context;自我驗證;如實標示 AI 產出範圍 |
| Reviewer | 檢查流程是否落實;core code 逐行 review;leaf node 抽查 |
| Module Owner | 守護核心架構;對觸及自己模組的 AI PR 有否決權 |
| Tech Lead | 監督規範落實;定期 audit AI PR 品質;每季重檢 leaf / core 分類;決定模型升級時的政策調整 |
| 每位成員 | 持續提升「向 AI 提問與驗證」的能力——這是未來的核心競爭力 |
結語:擁抱指數,但守住紀律
「今天你可以選擇不用 AI 編程。但一兩年後,如果你仍堅持每一行 code 都要自己寫,你會成為瓶頸。記住指數成長——這不是科幻,這是 product roadmap。」 — Erik Schluntz
擔心「現在的工程師沒有以前那種徒手痛苦的訓練」是合理的,但反過來說——用 AI 學東西的速度比以前快很多倍。以前架構決策好不好要兩年才知道,現在六個月就能驗證;願意投入時間學習的人,能在同樣時間累積 4 倍經驗。我們真正該避免的,是「滑過去就好」的心態:不去理解 AI 的產出、只求過 CI、只求 PR 過——短期可能交件,長期會失去判斷 AI 對錯的能力。
這份規範的精神,可以濃縮成一句話:
Ask not what Claude can do for you, but what you can do for Claude.
把自己當 PM,把 Claude 當有能力但需要明確指示的隊友。專注 leaf node、嚴守 core code、建立可驗證的檢查點、學會在 AI 上累積經驗——這就是團隊在 vibe coding 時代仍能交付高品質產品的關鍵。
如果你的團隊現在還沒有任何規範、卻已經有人在偷偷用 AI 寫 production code,我會建議從最小可行子集開始導入:先把 PR 模板上線、要求標示 AI 產出範圍、再加上 leaf / core 二分法——光這三件事就能擋掉大部分災難。剩下的可以邊做邊長。
演講來源:Erik Schluntz, 「Vibe coding in prod | Code w/ Claude」